Artificial Intelligence Self-study
Traditional AI (Symbolic AI)
- 基于:符号表示 + 数理逻辑 + 搜索 - 有明确规则,依靠算力。
- Appliance : 数学难题(Heuristic Algorithm),棋牌对抗(围棋),专家系统(输入病症,输出可能疾病)
- Related Algorithm:深搜(DFS) -> 广搜(BFS) -> Greedy Algorithm -> A* Algorithm -> Minimax(#棋)
the data structure of frontier in DFS is Stack.
the data structure of frontier in BFS is Queue.
Greedy algorithm add a weight in every node as an evidence to judge the current best choice.
A* Algorithm adds the cost of reaching this code to the weight of everynode to improve the efficiency of Greedy algorithm.
All of those algorithm is about how to find a best solution.
Machine Learning
- 推动: 现实的uncertainty 和 传统AI中规则边界难以划定
- 种类
- 分类和回归
- 回归问题(Regression):结果是数值。
- 分类问题(Classification):结果是类别(标签)。
- 聚类问题(Clustering):群组划分。
- 监督和无监督
- 监督学习:训练时提供完成的(x,y)
- 无监督学习(Unsupervised learning): 训练时仅提供(x),一般应用于集簇情况。但是,无监督学习生成的规则比监督学习生成的规则要更全面。,可能考虑到新的信息。并且极大扩充样本量
- 半监督学习:有部分完成的(x,y),部分仅有(x)。可以先进行无监督学习,在用完整部分进行验证修改。
- 强化学习
- 迁移学习
- 分类和回归
- Library: Scikit-Learn, know as Sklearn (针对机器学习,不支持深度学习和强化学习)
基本逻辑
- 函数(模型)-> 模型类型
- 参数(参数 与 超参数): 参数通过训练的得出,超参数一般为人为设定(有技术也可训练得出)
- 特征(输入 x)
- 目标(输出 y)
- 数据(训练数据)
- 学习率:在学习过程中,每一次调整参数的幅度。
给定模型,使用数据训练得出最优参数,从而损失函数最小。模型训练也就是损失函数优化。其中数据不一定都是对的,还可能存在反例(负样本)
训练流程
训练数据 -> 测试数据(保留30%训练数据来验证) -> 调整数据 -> 推理数据(应用)
回归分析(Regression Analysis)
- 根据数据,找出影响因素和结果之间的定量关系。
- 分类
- 一元回归(一个影响因素)和多元回归(多个影响因素)-> 变量数
- 线性回归(一条 y= ax + b 的直线)和 非线形回归(抛物线等) -> 函数关系
线性回归
- 属于监督学习。把所有样本放在坐标系(不一定几维)里,耦合出一个函数公式。
- 函数表达式:y = ax + b 等
- 为了寻找到损失函数的最小值(最优a、b),常会使用梯度下降法
梯度下降法:一种寻找最小值的方法。最优解也就是最符合规则的那条线,过多或过少都会导致损失函数的数值增大,所以是个二元一次方程(针对一元线性回归)。
操作:通过向函数上当前点对应的梯度的反方向按照 相同步长(学习率) 距离点进行迭代搜索,直到在最小点收敛(导数为0)。
缺点:不一定找到全局最低点,往往找到的是局部最低点
效果评估
- 损失函数(Loss Function):用于测量结果与实际之间的差距。越小越好。
J = 1 2 m ∑ i = 1 m ( y i , − y i ) 2
- 均方误差(MSE):越小越好。
M S E = 1 m ∑ i = 1 m ( y i , − y i ) 2
- R方值:越接近1越好
R 2 = 1 − ∑ i = 1 m ( y i , − y i ) 2 ∑ i = 1 m ( y i − y i ¯ ) 2 = 1 − M S E 方差
逻辑回归
- 用于解决二分类问题的逻辑回归方程:Sigmoid方程
Y = 1 1 + e − x
- 复杂问题的逻辑方程:
Y = 1 1 + e − g ( x )
其中,g(x)为划分边界(Decision Boundary)的边界函数。例如一条直线:
g ( x ) = Θ 0 + Θ 1 X 1 + Θ 2 X 2
其中,Θ 0也称之为Bias。后面也表示为Θ 0X0。
效果评估
分类问题,标签和结果都是离散的点,所以无法使用线性回归的损失函数。所以,在逻辑回归中,损失函数变为:
J = − 1 m [ ∑ i = 1 m ( y i log ( P ( x i ) ) + ( 1 − y i ) log ( 1 − P ( x i ) ) ) ]
过拟合(Overfitting)和欠拟合(underfitting)
- 造成原因:模型复杂度与问题不匹配。或者,训练过度依赖于特定数据,不具有一般性。
- 判断过拟合方法:学习曲线(Learning Curve),混淆矩阵(Confusion Matrix)。

从混淆矩阵得到分类指标
样例总数 = TP + FP + TN + FN。
Accuracy(精确率) = (TP+TN)/(TP+FN+FP+TN)
Precision(正确率) = TP/(TP+FP)
Recall(召回率) = TP/(TP+FN)
FDR(负正类率) = FP/(TN+FP)
Specificity(特异性) = 1 - FPR

-
解决过拟合部分方法
- 模型选择:减少影响参数 -> 把相关数据变为一个
- 特征选择:降低数据维度->用一维坐标表示二维带状分布
- 大数据:增大样本量
- 模型聚合及其变形
- 正则化(regularization): 也就是给损失函数后面加一个正则项。例如:线性回归的最小损失函数为:
J = 1 2 m ∑ i = 1 m ( y i , − y i ) 2 = 1 2 m ∑ i = 1 m ( g ( Θ , x i ) − y i ) 2
添加正则项后,损失函数变为:
J = 1 2 m ∑ i = 1 m ( g ( θ , x i ) − y i ) 2 + λ 2 m ∑ j = 1 n θ j 2
或
J = 1 2 m ∑ i = 1 m ( g ( θ , x i ) − y i ) 2 + λ 2 m ∑ j = 1 n | θ j |
当 λ取值大的情况下,可约束θ取值,从而有效控制各个属性数据的影响。
上方二次方的正则称之为 岭回归-L2正则化
下方绝对值的正则称之为 Lasso回归-L1正则化
聚类问题
- 聚类分析:也成群分析,根据对象有些属性的相似性,将其自动划分为不同的类别。
常见聚类算法
KMeans算法 (K均值聚类)
以空间中K个点为中心进行聚类,对最靠近他们的对象进行归类。
- 流程
- 根据数据与中心点的距离划分类别。
- 基于类别数据更新中心点。
- 重复过程直至收敛。
- 特点
- 实现简单,速度快。
- 但是,需要指定类别数量
Meanshift(均值偏移)
- 流程
- 在中心点一定区域检索数据
- 更新中心
- 重复过程直至收敛
- 特点
- 自动发现类别数量,不需要人工选择
- 需要给定区域半径
DBSCAN算法 (基于密度的空间聚类算法)
- 流程
- 基于区域点密度筛选有效数据。
- 基于有效数据向周边扩张,直至没有新点加入。
- 特点
- 过滤噪声数据。
- 不需要人为选择类别数据。
- 数据密度不同时,影响结果。
决策树
决策树有点像if语句,这种机械学习算法可解释性强。
Deep Learning
神经网络(多层感知器,前馈神经网络)
- 优势:在不增加高次项的情况下,轻易解决非线性分类问题。
逻辑回归也能解决神经网络的问题。但是当X(影响参数)增加的情况下,逻辑表达式g(x)里会显著增加高次项如 X2和Xn,或 XnXn+1的个数。增大计算难度。
感知器
模仿人类神经元。对不同的输入因子乘以对应权重相加,随后将结果二项化,输出。

其中上图中的 f, 类似于Sigmoid函数,将结果落在 [0,1]。该函数称之为激活函数。
一个神经元,其实就是一个逻辑回归模型。
激活函数(Activation Function)
Sigmoid 函数
- 表达式:
Y = 1 1 + e − x
-
优点
- 贴近物理意义上神经元
- 求导容易
-
缺点
- 由于软饱和性,易产生梯度消失 (在两侧贴近极值) ,导致训练出问题
- 其输出不是以0为中心。[0,1]
-
图形:

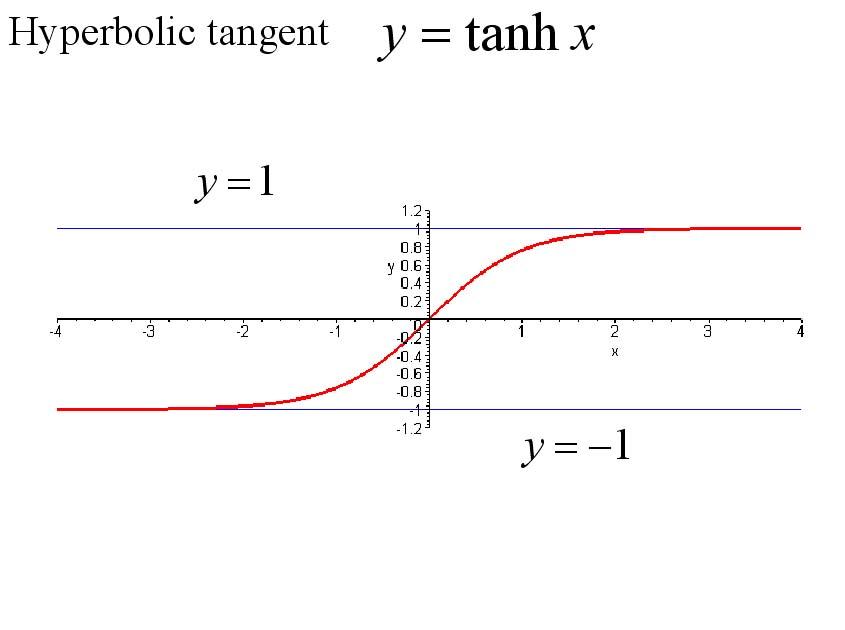
Tanh函数(双曲正切,双曲函数之一)
- 表达式:
Y = 1 − e − 2 x 1 + e − 2 x
-
优点
- 比Sigmoid函数收敛更快
- 以0为输出中心
-
缺点
- 易产生梯度消失 (在两侧贴近极值) ,导致训练出问题
-
图形:
ReLU函数(Rectified Linear Unit,整流线性单位函数)
用于隐层神经元输出。
- 表达式:
Y = max ( 0 , x )
-
优点
- 由于线性、非饱和形式,可以快速收敛
- 有效缓解梯度消失问题
- 提供神经网络的稀疏表达能力
-
缺点
- 随着训练的进行,可能会出现神经元死亡,权重无法更新。那么流经神经元的梯度永远是0。也就是ReLU神经元在训练中不可逆的死亡了。
-
图形:

多层感知器

左侧叫输入神经元(Input Layer, 输入层),中间的叫隐含神经元(Hiden Layer, 隐藏层),右侧叫输出神经元(Output Layer, 输出层)。
如果要增加多分类预测,则增加输出神经元个数即可。神经网络本质上就是函数嵌套。隐藏层的每一层都是对上一层的抽象与归纳。
每一个神经元都与下一层的所有神经元连接,称之为全连接。
- 反向传播:由于神经网络很难通过一个函数表示,所以无法用线性回归或逻辑回归的Loss Function来修正。神经网络本质上就是函数嵌套,从后往前,将每一层每个节点进行梯度计算,最终确定偏差点来源,然后更新。这个过程叫反向传播。
- 为什么需要更深的网络?更深的网络可以减少模型参数;可形成语义结构层次;更容易训练。
Dropout (“dropout” regularization)
我们每一次训练时,随机删除部分神经元,这样可以有效避免一个神经网络过拟合。

批规范化(Batch Normalization)
其本质上是在训练过程加入噪音 , 从而让模型得到更好的鲁棒性 , 其特性令超深神经网络可以更好的训练。如果使用ReLU,其取值是[0,正无穷]。批规范化就是将结果规约到[0,1]。
数据增强
- 作用:增加样本量,增加泛化能力。
- 方法:
- 旋转
- 翻转
- 缩放
- 加入噪声
- 截取
- 加入弹性畸变
CNN(卷积神经网络)
- 主要用于空间相关性模型。
为什么全连接神经网络不能处理图像相关问题?
因为参数输入会非常非常大。如果一个100*100的图像去学习。那么参数就有100*100*3个参数。
并不是每个像素我们都需要,所以全连接没有必要。
全连接把拓扑结构破坏了。二维变成了一维。而CNN接受的输入是图像。
- 结构: 输入层 -> 卷积层(提取特征)-> 池化(压缩特征) -> 全连接层 -> 输出层
卷积层

上面演示的卷积,是保持图片尺寸的卷积。如果我们仅对有像素的位置进行卷积,就可以缩小图片尺寸。
对于图像的卷积,操作方式是图像的RGB分量分别进行卷积进行相加,最后还要添加bias。最终得到的图片叫特征图(Feature Map)
- 步长: 每次向右移动的个数。影响特征图的尺寸。
- 卷积核尺寸:Fliter的尺寸。
- 边缘填充:弥补边缘数据使用不充分的问题。一般进行0填充。
- 卷积核个数:需要得到几个特征图,就要有多少卷积核。
- 卷积核尺寸计算公式: S是步长,P是边缘填充个数。
H r = H 1 − F H + 2 P S + 1
- 每个卷积层后面一定要接一个激活函数。
池化层(Pooling)
池化层其实就是对特征图进行筛选。保留重要信息的基础上,对图片的尺寸进行缩减。跟卷积相似,其中也有步长。
如下图,就是步幅为2,池化窗口为2×2的最大池化层

AlexNet

VGGNet
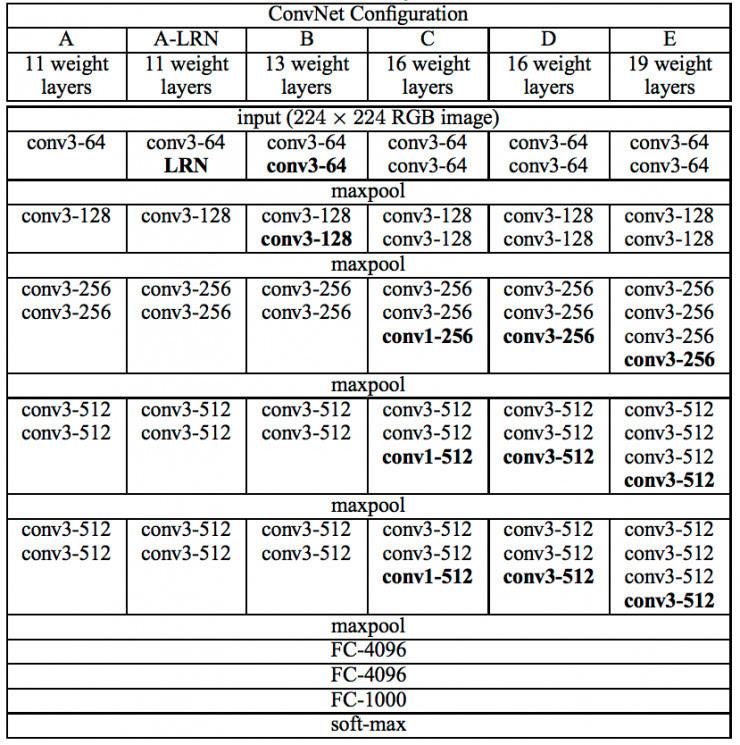
ResNet
随着层数增加,反向传播的难度便会增加,使得模型调优变得困难。并且如果有一层学习效果不好,后续学习过程将会变成无用。ResNet解决了该问题。

如果发现一部分层学习效果不好。就把参数做成0,相当于把一部分层drop了。
RNN(循环神经网络)
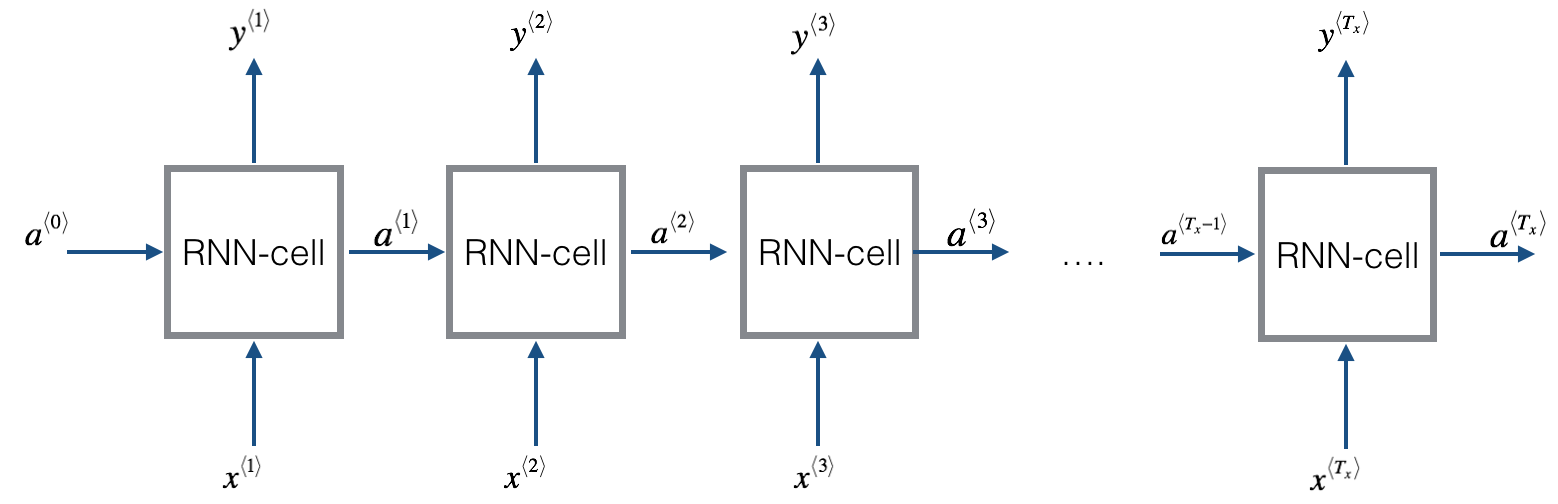
- 关系式:
a ( T x ) = g a ( θ a a a ( T x − 1 ) + θ a x x ( T x ) + θ a )
y ( T x ) = g y ( θ y a a ( T x − 1 ) + θ y x x ( T x ) + θ y )
为什么需要循环神经网络?
在部分场景中,每个单元并不是独立依存的,而是有前后联系的。
例如:自动寻找语句中的人名。(多输入-多输出模型)
The courses are taught by Flare Zhou and David Chen.
例如:情绪识别 (多输入-单输出模型)
I feel happy watching TV. -> Positive.
例如:序列数据生成- 音乐, 文章。(单输入-多输出模型)
例如:语言翻译 (多输入-多输出模型,input != output)
What is artificial intelligence? -> 什么是人工智能?
- 缺陷:普通RNN模型,只跟前面最直接的单元有影响,在信息传递过程中,信息权重下降,导致重要信息丢失。
信息丢失场景:
The student, who got A in the exam, ____ excellent.
LSTM (长短期记忆网络)

LSTM的逻辑就是添加一个记忆细胞来记住一些重要的信息。在算法流程里,每一个单元都可以丢弃一些H与X中不重要的信息,也可以更新C中重要的信息。
BRNN(双向循环神经网络)
BRNN 可以在做判断的时候,把后部的信息也考虑进来。

可以看到正负向传播的node之间是没有连接的,最后都指向输出的node。
得到误差函数后,正向逆向参数更新可以分别当作单独的RNN进行逆向传播。
Transfer Learning(迁移学习)
其中思想就是,在很深的一个网络里,针对不同任务,其部分神经元的排列组合可以进行复用。例如,在分辨数字和字母中,前面分辨部分是可以复用的,只有在后面语义部分,才会有显著差异。
所以,迁移学习的思想就是封装与复用。